












所有平台仅提供服务对接功能,所载文章、数据仅供参考,股市有风险,投资需谨慎,用户需独立做出投资决策,风险自担!

时间:2021-12-21 13:58:02来源:
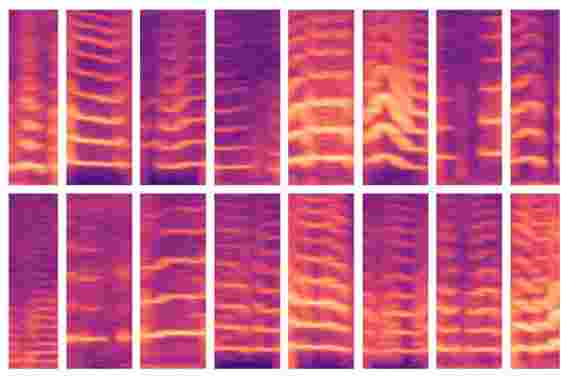
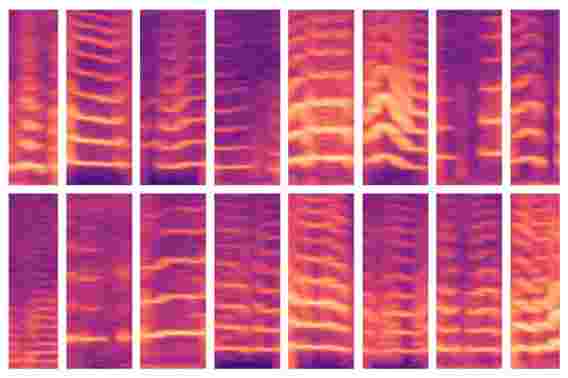
麻省理工学院开发的新模型使使用AI进行医学决策的关键步骤实现了自动化,专家通常可以手动识别大量患者数据集中的重要特征。该模型能够自动识别具有声带结节的人的发声模式(如图所示),然后使用这些功能来预测哪些人患有或没有这种疾病。
麻省理工学院的计算机科学家希望通过自动化通常由人工完成的关键步骤来加快人工智能的使用,从而改善医疗决策,而随着某些数据集变得越来越大,这一点变得越来越费力。
预测分析领域在帮助临床医生诊断和治疗患者方面具有越来越大的前景。仅举几个例子,可以训练机器学习模型来找到患者数据中的模式,以帮助进行败血症护理,设计更安全的化疗方案以及预测患者罹患乳腺癌或死于ICU的风险。
通常,训练数据集由许多患病和健康的受试者组成,但每个受试者的数据相对较少。然后,专家们必须在数据集中找到对于做出预测非常重要的那些方面或“特征”。
这种“功能工程”可能是一个费力且昂贵的过程。但是随着可穿戴式传感器的兴起,挑战变得更加严峻,因为研究人员可以更轻松地长期监控患者的生物特征,例如跟踪睡眠方式,步态和声音活动。在只进行了一周的监视之后,专家们可以针对每个主题获得数十亿个数据样本。
在本周的医疗保健机器学习会议上发表的一篇论文中,麻省理工学院的研究人员演示了一种可自动学习预测声带疾病特征的模型。这些功能来自大约100个主题的数据集,每个主题都有大约一周的语音监视数据和数十亿个样本-换句话说,主题数量很少,每个主题的数据量很大。数据集包含从安装在对象脖子上的小加速度传感器获取的信号。
在实验中,该模型使用从这些数据中自动提取的特征对具有和没有声带结节的患者进行高精度分类。这些是在喉部形成的病变,通常是由于声音滥用的方式(例如敲出歌声或大喊大叫)所致。重要的是,该模型无需大量手工标记的数据即可完成此任务。
“收集长时间序列的数据集变得越来越容易。但您有需要将其知识应用于数据集标签的医师。”主要作者Jose Javier Gonzalez Ortiz博士说。麻省理工学院计算机科学与人工智能实验室(CSAIL)的学生。“我们希望为专家删除该手册部分,并将所有功能工程卸载到机器学习模型中。”
该模型可以适于学习任何疾病或状况的模式。研究人员说,但是检测与声带结节相关的日常语音使用模式的能力是开发预防,诊断和治疗该疾病的改进方法的重要一步。这可能包括设计新的方法,以识别和提醒人们潜在的破坏性声音行为。
与冈萨雷斯·奥尔蒂斯(Gonzalez Ortiz)一起发表论文的是约翰·古塔格(John Guttag),他是Dugald C. Jackson计算机科学与电气工程学教授,也是CSAIL数据驱动推理小组的负责人;罗伯特·希尔曼(Robert Hillman),贾拉德·范斯坦(Jarrad Van Stan)和达拉什·梅塔(Daryush Mehta),都是麻省总医院喉外科和语音康复中心;多伦多大学计算机科学与医学助理教授Marzyeh Ghassemi。
强制特征学习
多年来,麻省理工学院的研究人员一直与喉外科和语音康复中心合作,开发和分析来自传感器的数据,以在所有清醒时间内追踪受试者的语音使用情况。该传感器是一个加速度计,其节点粘在脖子上并连接到智能手机。当人们交谈时,智能手机会从加速度计中的位移中收集数据。
在他们的工作中,研究人员从104位受试者中收集了一周的此类数据(称为“时间序列”数据),其中一半被诊断出有声带小结。对于每个患者,还有一个匹配的对照,这意味着年龄,性别,职业和其他因素相似的健康受试者。
传统上,专家将需要手动识别对于模型检测各种疾病或状况可能有用的特征。这有助于防止医疗保健中常见的机器学习问题:过度安装。那时,在训练中,模型可以“记住”受试者数据,而不仅仅是学习与临床相关的功能。在测试中,这些模型通常无法分辨以前看不见的主题中的相似模式。
“模型没有看到具有临床意义的特征,而是看到了模式并说:‘这是莎拉,我知道莎拉很健康,这是彼得,有声带小结。”因此,这只是在记住主题的模式。然后,当看到来自Andrew的数据时,它具有新的声音使用模式,就无法确定这些模式是否与分类匹配。冈萨雷斯·奥尔蒂斯说。
因此,主要的挑战是在使手动要素工程自动化的同时防止过度拟合。为此,研究人员强迫该模型学习没有主题信息的特征。对于他们的任务,这意味着捕捉对象说话时的所有时刻以及他们声音的强度。
当他们的模型浏览主题的数据时,会对其进行编程以定位发声段,该发声段仅占数据的10%。对于这些发声窗口中的每一个,模型都会计算一个频谱图,该频谱图是随时间变化的频率频谱的直观表示,通常用于语音处理任务。然后将频谱图存储为数千个值的大型矩阵。
但是这些矩阵巨大且难以处理。因此,自动编码器(一种经过优化可从大量数据生成有效数据编码的神经网络)首先将频谱图压缩为30个值的编码。然后将其解压缩为单独的频谱图。
基本上,模型必须确保解压缩的频谱图与原始频谱图输入非常相似。这样一来,就必须学习每个主体整个时间序列数据上每个频谱图片段输入的压缩表示形式。压缩表示形式是帮助训练机器学习模型进行预测的功能。
映射正常和异常特征
在训练中,模型学习将那些特征映射到“患者”或“控件”。患者将具有比对照组更多的发声模式。在对以前看不见的主题进行测试时,该模型类似地将所有频谱图片段压缩为一组简化的特征。然后,这是多数规则:如果受试者的话音片段大多异常,则将其归类为患者;如果他们大部分是正常人,则将其归为控件。
在实验中,该模型的执行效果与需要手动特征工程的最新模型一样准确。重要的是,研究人员的模型在训练和测试中均能准确执行,这表明该模型是从数据中学习临床相关模式,而不是从特定受试者的信息中学习。
接下来,研究人员想监测各种治疗方法(例如手术和声乐疗法)如何影响声乐行为。如果患者的行为随着时间的推移从异常变为正常,则很有可能会得到改善。他们还希望对心电图数据使用类似的技术,该技术可用于跟踪心脏的肌肉功能。
声明:文章仅代表原作者观点,不代表本站立场;如有侵权、违规,可直接反馈本站,我们将会作修改或删除处理。







图文推荐
2021-12-21 13:58:00

2021-12-21 12:58:00

2021-12-21 11:58:00

2021-12-21 10:58:00

2021-12-21 09:58:00
2021-12-21 08:58:00
热点排行
精彩文章
2021-12-21 13:58:02

2021-12-21 12:58:01

2021-12-21 11:58:02
2021-12-21 10:58:02

2021-12-21 09:58:02

2021-12-21 08:58:02
热门推荐
