












所有平台仅提供服务对接功能,所载文章、数据仅供参考,股市有风险,投资需谨慎,用户需独立做出投资决策,风险自担!

时间:2021-11-11 11:58:06来源:
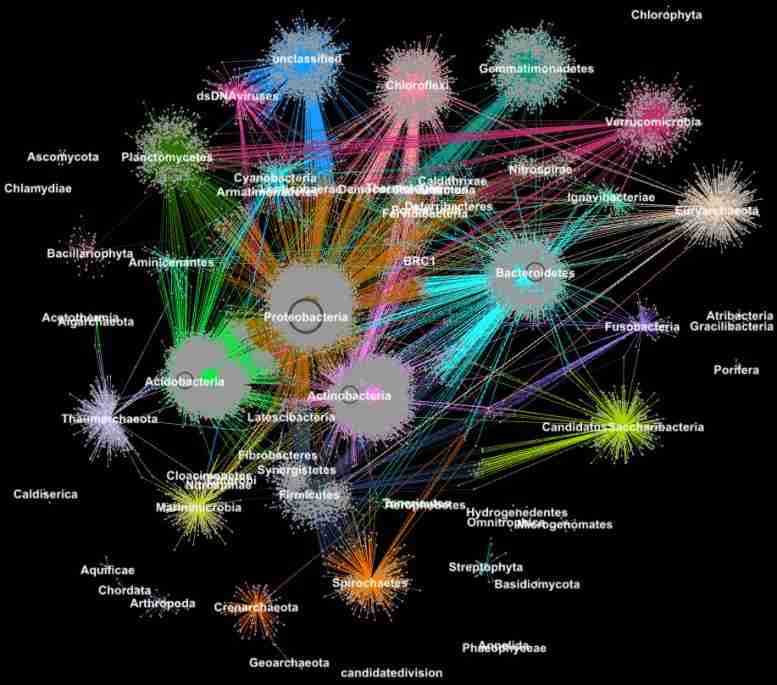
根据其分类分类分类,来自Metagenomes的蛋白质聚集在家庭中。(
您是否知道用于分析社交网络用户或排名网页之间关系的工具,对拟大科学数据感也非常有价值?在像Facebook这样的社交网络上,每个用户(人或组织)都被表示为节点,并且它们之间的连接(关系和交互)称为边缘。通过分析这些联系,研究人员可以了解大量关于每个用户兴趣,爱好,购物习惯,朋友等。
在生物学中,类似的图形聚类算法可用于理解执行大多数生命功能的蛋白质。据估计,单独的人体含有约100,000种不同的蛋白质类型,并且几乎所有生物任务 - 当这些微生物相互作用时发生消化对抗免疫。更好地理解这些网络可以帮助研究人员确定药物的有效性或识别各种疾病的潜在治疗方法。
如今,先进的高吞吐量技术允许研究人员在一系列环境条件下捕获数百万种蛋白质,基因和其他细胞组分。然后将聚类算法应用于这些数据集以识别可能指向结构和功能相似性的模式和关系。虽然这些技术已被广泛使用超过十年,但它们不能跟上下一代测序仪和微阵列产生的生物数据的洪流。实际上,很少有现有算法可以聚类包含数百万节点(蛋白质)和边缘(连接)的生物网络。
这就是为什么来自能源部(Doe)劳伦斯伯克利国家实验室(伯克利实验室)和联合基因组研究所(JGI)的研究人员团队占据了现代生物学中最受欢迎的聚类方法之一 - Markov聚类(MCL)算法 - 和将其修改为在分布式存储器超级计算机上快速,有效地和缩放运行。在测试用例中,他们的高性能算法 - 名为HIPMCL - 实现了先前不可能的壮举:在几个小时内使用大约140,000个处理器核心的大约140,000个处理器核心,聚类了一个大约7000万节点和680亿边缘的大型生物网络科学计算中心(NERSC)CORI超级计算机。一篇描述这项工作的论文在核酸研究期间最近发表于核酸研究。
“Hipmcl的真正好处是它能够与现有的MCL软件集群不可能集群的大规模生物网络,从而允许我们识别和表征微生物社区中存在的新功能空间,”尼克斯·克罗佩斯说,谁头JGI微生物组数据科学努力和原英尺超级计划,并是本文的共同作者。“此外,我们可以在不牺牲原始方法的任何敏感度或准确性的情况下,这始终是这些缩放工作中的最大挑战。”
“随着我们的数据增长,我们正在变得更加迫切,我们将工具移动到高性能计算环境中,”他补充道。“如果你要问我蛋白质空间有多大?事实是,我们真的不知道,因为到目前为止我们没有计算工具,以有效地聚集所有基因组数据并探测功能性暗物质。“
除了数据收集技术的进步之外,研究人员越来越多地选择在社区数据库中与综合微生物基因组和微生物体(IMG / M)系统(IMG / M)系统相同,这是通过JGI和Berkeley Lab的科学家之间的数十年来开发的计算研究司(CRD)。但是,通过允许用户根据其偏心序列进行比较分析并探索微生物群群的功能能力,IMG / M等社区工具也有助于技术爆炸。
如何随机走向计算瓶颈

Cori超级计算机在国家能源研究科学计算中心(NERSC)。照片作者Roy Kaltschmidt,伯克利实验室
为了获得这种数据的洪流,研究人员依赖于集群分析或聚类。这基本上是对象的任务,使得同一组中的项目(群集)比其他集群中的项目更相似。十多年来,计算生物学家赞成通过相似性和相互作用来聚类蛋白质的MCL。
“MCL在计算生物学家中受欢迎的原因之一是它是免费参数的;用户不必设置大量的参数以获得准确的结果,并且对数据的小型更改非常稳定。这很重要,因为您可能必须重新定义数据点之间的相似性,或者您可能必须纠正数据中的略微测量错误。在这些情况下,您不希望您的修改将分析从10个集群更改为1000个集群,“AydinBuluç说,CRD科学家和本文的共同作者之一。
但是,他补充说,计算生物学社区正在遇到计算瓶颈,因为该工具主要在单个计算机节点上运行,用于执行昂贵的昂贵,并且具有大的存储器占用空间 - 所有这些算法可以集群的数据量限制了该算法的数据量。
该分析中最具计算和内存的密集密集型步骤之一是一个名为随机散步的过程。该技术量化节点之间的连接的强度,这对于在网络中进行分类和预测链路是有用的。在互联网搜索的情况下,这可能会帮助您在旧金山找到一个廉价的酒店房间,用于春假,甚至告诉您预订它的最佳时间。在生物学中,这样的工具可以帮助您识别有助于您的身体对抗流感病毒的蛋白质。
给定任意图形或网络,很难知道访问所有节点和链接的最有效方式。随机探索整个图表,随机步行会出现足迹;它在节点开始,沿着边缘任意移动到相邻节点。此过程一直在达到图形网络上的所有节点之前。因为网络中节点之间存在许多不同的行驶方式,所以这一步骤重复多次。像MCL这样的算法将继续运行此随机步行过程,直到迭代之间不再有显着差异。
在任何给定的网络中,您可能有一个节点,该节点连接到数百个节点以及仅具有一个连接的节点。随机散步将捕获高度连接的节点,因为每次运行过程时都会检测到不同的路径。利用此信息,该算法可以通过确定网络上的节点连接到另一个级别的确定性。在每个随机漫游运行之间,该算法标记其对像马尔可夫矩阵类型的栏中的图表上的每个节点的预测,就像在终点和最终集群一样透露。它听起来很简单,但对于蛋白质网络具有数百万节点和数十亿的边缘,这可能成为一个极其计算和内存密集问题。伯克利实验室计算机科学家们使用了尖端数学工具来克服这些限制。
“我们明显保持了MCL骨干层,使HIPMCL成为原始MCL算法的大规模平行实现,”CRD和纸张铅作者的计算机科学家省级Azad说。
虽然之前尝试并行化MCL算法在单个GPU上运行,但由于GPU的内存限制,该工具仍然只能纳入相对较小的网络。
“通过HipMCL,我们基本上返工了MCL算法,以有效地运行,并在数千个处理器上并行地运行,并将其设置为利用所有计算节点中可用的聚合存储器,”他补充道。“HIPMCL的前所未有的可扩展性来自其对稀疏矩阵操纵的最先进算法的使用。”
根据Buluç,使用稀疏矩阵矩阵乘法最佳地计算来自图表的许多节点的随机步行,这是最近发布的图形标准中最基本的操作之一。Buluç和Azad开发了一些最可扩展的并行算法,用于Graphblas的稀疏矩阵矩阵乘法,并修改了其最先进的HIPMCL算法之一。
“这里的症结是在并行性和内存消耗之间取得正确的平衡。HipMCL在鉴定分配给它的可用内存时,尽可能多地提取并行度。“Buluç说。
Hipmcl:在比例中聚类
除了数学创新之外,HIPMCL的另一个优点是它在任何系统上无缝运行的能力 - 包括笔记本电脑,工作站和大型超级计算机。研究人员通过在C ++中开发其工具并使用标准MPI和OpenMP库来实现这一目标。
“我们在NERSC的英特尔Haswell,Ivy Bridge和Knights登陆处理器上广泛测试了Hipmcl,使用最多2,000个节点和所有处理器上的半百万线程,并且在所有这些过程中运行HipMCL成功集群网络,包括数千百万到数十亿的边缘, “Buluç说。“我们看到它可以使用它可以使用的处理器数量的障碍,并发现它可以比原始MCL算法快1000倍的群集网络。”
“HipMCL将是大数据的计算生物学的真正转型,就像IMG和IMG / M系统已经用于微生物组基因组学一样,”克罗佩德说。“这种成就是伯克利实验室跨学科合作的效益。作为生物学家,我们了解科学,但能够与计算机科学家合作,可以帮助我们解决我们的局限性并推动我们前进的计算机科学家已经如此非常宝贵。“
他们的下一步是继续为未来的ExaScale系统继续返回HipMcl和其他计算生物学工具,这将能够计算每秒千万零计算。这将是必不可少的,因为基因组学数据继续在令人难以置信的速率下降大约每五到六个月的令人沮丧的速度。这将作为Doe ExaScale计算项目的exagraph Co-Design Center的一部分。
出版物:Aliful Azad等,“HipMCL:大规模网络的马尔可夫聚类算法的高性能并行实施,”核酸研究,2018; DOI:/10.1093/NAR/GKX1313
声明:文章仅代表原作者观点,不代表本站立场;如有侵权、违规,可直接反馈本站,我们将会作修改或删除处理。







图文推荐

2021-11-11 11:58:02

2021-11-11 10:58:00

2021-11-11 09:58:00

2021-11-11 08:58:02
2021-11-10 19:58:00

2021-11-10 18:58:02
热点排行
精彩文章

2021-11-11 11:58:04
2021-11-11 10:58:02
2021-11-11 09:58:01
2021-11-11 08:58:04

2021-11-10 19:58:02

2021-11-10 18:58:04
热门推荐
